by Natalie Mueller
Machine Translation. It’s both the best friend and worst enemy of not only language learners, but anyone on the Internet trying to understand content in another language. It’s a tool that has garnered a fair amount of research attention as a subfield of Natural Language Processing, but even tech giants seemingly struggle in creating effective models to accomplish this task. This is exemplified by the infamy of Machine Translation applications such as Google Translate. While it’s useful for translating words and short phrases, anything longer than a few sentences seems to become incomprehensible. Why is that?
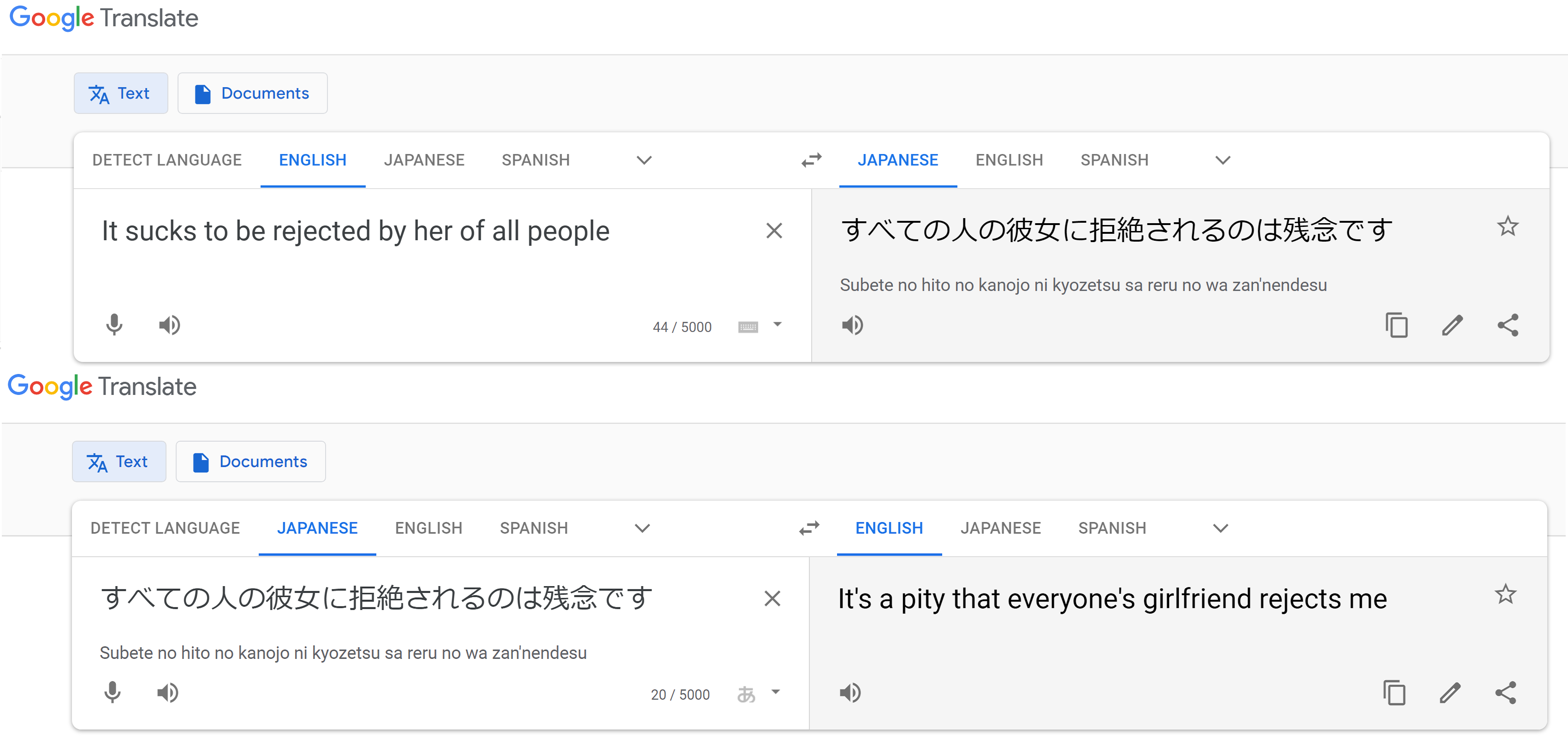
To create a basis for comparison, I decided to analyze three translated versions of Race to the Lunar World:

one produced by Google Translate (our infamous machine translator),

one produced by DeepL (a more “human-like” machine translator),

and one produced by me (a human).
In Race to the Lunar World, I have translated Shunrō Oshikawa’s 月世界競争探検 (Gessekai Kyousou Tanken, lit. Competitive Expedition to the Lunar World), which was originally published in 1907, 62 years before the first moon landing. This short story follows the journey of Fumihiko Kumoi and Baron Akiyama as they race to the moon in search of Dr. Sasayama, a university professor who mysteriously disappeared after traveling there for research. Oshikawa’s writing reflects his imagination and artistry, something that machine translation has difficulty capturing.
Pop Quiz!
The sentence 再びその洞を出て元来た道に引返した (lit. He left the cave and turned back to the path he came from.) has been translated by our three translators. Which of these was written by a human?
Let’s start by talking about one of the smaller meaningful units of language - words. Machine Translation models tend to perform well with individual words because the translation becomes a matter of probability. Models are built so that two words with similar definitions will have a high probability of translating to each other. Of course, a word’s definition isn’t the only aspect that needs to be considered in translation – there’s also the context that a word appears in, a challenging but essential part of accurate translation. How should context be represented in a model? How does the model determine which context is relevant? While the comprehensibility of DeepL’s translation greatly outperformed Google’s, there are some recurring flaws occurring in both, and context plays a big role in this.

The Google Translate model had instances of translating waka danna-sama (Young Master) as “young husband”,1 and in both models, there were also cases of a character’s name being spelled differently each time it was written. For example, the character Tōsuke was referred to at various times as “Tōsuke”, “Tousuke”, “Toasuke”, and “Azumasuke”. Machine Translation models teach themselves how to behave based on training data that they are given and some pre-set parameters. Training data often consists of text, whether it’s from the news, the Internet, literature, etc. Usually, two copies are provided, one in both the source and target languages (Japanese and English in this case) for direct comparison. The model then analyzes these documents and forms some ideas about how the patterns between the two languages work, and the context that a word appears in usually has a lot of weight here.
Context Search!
When we search for context, we have the luxury of being able to look at the entire paragraph. However, in some machine translation models, they can only look at a certain number of words before and/or after the current word. Even then, it can be hard to decide what exactly a pronoun is referring to. Drag the arrow to compare human (left) and machine (right) context views.

Knowing this, the logic behind the common mistakes both models made when translating Race to the Lunar World becomes clearer. In modern Japanese, 旦那 (danna) has shifted to mean “husband” much more often than it means “master”. If the training data is pulled mostly from modern Japanese text, then the model will decide based on its past understanding that “husband” is statistically more likely to be the correct translation. However, given the age of the story and the previous mention of an assistant character, humans can tell that the correct answer here is actually “master”. Moreover, the name spelling changes are likely a result of something similar. The model didn’t realize that all those spellings were just different versions of the same name, so it treated each name like an individual word. Based on the contexts those spellings appeared in in the training text, the model choose the one that it believed was statistically most likely to be correct.

On the flip side, this also explains how these models perform so well in terms of localization techniques such as using romaji2 to translate a name instead of literally translating what each kanji3 in their name means. In analyzing the English versions of Japanese text, the model picks up the localization techniques used by the original human translator and applies them well.

Another aspect worth mentioning is sentence structure, which arguably makes Google Translate the most difficult to understand. Irregular sentence structure is a product of the strategies each model uses to address word order. While English uses Subject-Verb-Object (SVO) sentence structure, Japanese uses Subject-Object-Verb (SOV). Most Machine Translation models are built under the conditions that they will translate between SVO languages, so they have built-in mechanisms that prevent the model from rearranging the phrases in a sentence too much. While this is beneficial for the original use case, these mechanisms end up hurting the model’s performance in situations where large rearrangements of the sentence structure are actually necessary. Google Translate seems to do very little word reordering in its translations, so the result becomes practically unreadable because the grammar does not follow English grammar conventions. Research detailing ways to improve word reordering techniques is still new, which makes DeepL’s ability to create a comprehensible translation that reflects the original story a very impressive feat.
So, what does this all mean for the future of machine translation? Considering how young the field is, there have been some great strides thus far and the results of new studies are very promising. Future work will likely expand beyond building models that only work for certain language structures and move toward universal translation techniques. However, many hurdles still stand in the way of such a lofty goal, so it could be years before our technology develops to that point. But when we finally get there, universal translation will allow communication that can bring humanity even closer together.
1 Note that 旦那 (danna) can mean both “master” or “husband” depending on the context.
2 Romaji refers to Japanese words that have been romanized. For example, words like sushi and kimono, or names like Tanaka and Suzuki are adopted into English words based on how they sound when pronounced in Japanese. This is typically used when there is no equivalent word or phrase in English.
3 Kanji refers to the Chinese characters used in written Japanese. Japanese names are typically made up of kanji, and each kanji has its own meaning and pronunciation. For example, the name Tōsuke is written as 東助 in the original story, consisting of kanji meaning "east” and “help”. Most human translators will agree that it makes more sense to overseas audiences if we refer to him the way his name is pronounced (Tōsuke) instead of what his name literally means (east help).
© 2021 by Natalie Mueller.
About the Author
Natalie Mueller is an undergraduate student at the Georgia Institute of Technology, where she’s majoring in Computer Science and minoring in Japanese. Her concentration is in Artificial Intelligence, and she is currently studying topics like Natural Language Processing and Computer Vision. She was inspired to work in the intersection of interactive media and speculative fiction by her love of tabletop role-playing games like Dungeons & Dragons, World Wide Wrestling, Paranoia, and Blades in the Dark.